
機械学習
すべての組織は現在、よりデータ駆動型の試みを行っています。機械学習の手法は、この取り組みに役立ちました。私は、世の中の多くの資料が技術的すぎて理解しにくいことを知っています。この一連の記事では、私の目的はデータサイエンスを簡素化することです。私はスタンフォードの講座、本から手がかりを得ています。この試みは、誰にとってもデータサイエンスを理解しやすくすることです。
1.ビジネスの問題を定義する
Albert Einsteinがかつて引用した「すべてをできるだけシンプルにする必要がありますが、シンプルではありません」。この引用は、ビジネス上の問題を定義する際の核心です。例を説明しましょう。通信会社が顧客ベースの減少により、前年比で収益が減少したと仮定します。このシナリオでは、ビジネス上の問題は次のように定義されます。
- 会社は、新しいセグメントをターゲットにし、顧客離れを減らすことで顧客ベースを拡大する必要があります。
2.機械学習タスクに分解する
ビジネス上の問題は、一度定義したら、機械学習タスクに分解する必要があります。上記で設定した例について詳しく説明しましょう。組織が新しいセグメントをターゲットにし、顧客離れを減らすことで顧客ベースを拡大する必要がある場合、機械学習の問題にどのように分解できますか?分解の例を次に示します。
- 顧客の解約をx%削減します。
- ターゲットマーケティングの新しい顧客セグメントを特定します。
3.データの準備
ビジネスの問題を定義し、機械学習の問題を分解したら、データをさらに深く掘り下げる必要があります。データの理解は、当面の問題を明示する必要があります。分析のための適切な種類の戦略を開発するのに役立つはずです。注意すべき重要な点は、データのソース、データの品質、データバイアスなどです。
4.探索的データ分析
同様に、データサイエンティストは、データ内のパターンの未知の部分を横断し、その特性の陰謀を覗き、未探索を定式化します。探索的データ分析(EDA)は刺激的な作業です。データをよりよく理解し、ニュアンスを調査し、隠れたパターンを発見し、新しい機能を開発し、モデリング戦略を策定します。モデリングEDAの後、モデリングフェーズに進みます。ここでは、特定の機械学習の問題に基づいて、回帰、決定木、ランダムフォレストなどの有用なアルゴリズムを適用します。
5.モデリング
EDAの後、モデリングフェーズに進みます。ここでは、特定の機械学習の問題に基づいて、回帰、決定木、ランダムフォレストなどの有用なアルゴリズムを適用します。
6.展開と評価
最後に、開発されたモデルが展開されます。それらは、実際の世界での動作を観察するために継続的に監視され、それに応じて調整されます。通常、モデリングと展開の部分は作業のわずか20%です。作業の80%は、データを手でし、データを探索して理解することです。
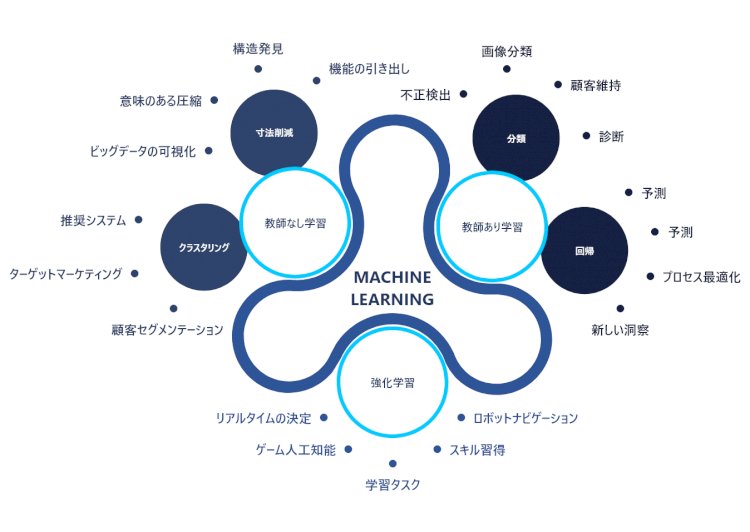
機械学習の問題タイプ
一般に、機械学習には2種類のタスクがあります。
教師あり学習
教師あり学習は、定義されたターゲットがある機械学習タスクの一種です。概念的には、モデラーは機械学習モデルを監督して特定の目標を達成します。教師あり学習は、さらに2つのタイプに分類できます。
回帰
回帰は、機械学習タスクの主力です。これらは、数値変数を推定または予測するために使用されます。次のような回帰モデルの例はほとんどありません。
- 次の四半期の潜在的な収益の推定値は?
- 来年何件の取引を成立させることができますか?
分類
分類モデルは何かを分類します。どのバケットが最適かを推定します。分類モデルは、あらゆる種類のアプリケーションで頻繁に使用されます。分類モデルのいくつかの例は次のとおりです。
- スパムフィルターは、分類モデルの一般的な実装です。ここでは、すべての受信メールが特定の特性に基づいてスパムまたは非スパムとして分類されます。
- 予測の予測は、分類モデルのもう1つの重要なアプリケーションです。電話会社で広く使用されている解約モデルは、特定の顧客が解約するか(つまり、サービスの使用を停止するか)分類します。
教師なし学習
教師なし学習は、ターゲットがない機械学習タスクのクラスです。教師なし学習には特定の目標がないため、解き放つ結果は解釈が難しい場合があります。教師なし学習タスクには多くの種類があります。主なものは次のとおりです。
- クラスタリング:クラスタリングは、類似したものをグループ化するプロセスです。顧客のセグメンテーションでは、クラスタリング手法を使用します。
- 関連付け:関連付けは、互いに頻繁に一致する製品を見つける方法です。小売のマーケットバスケット分析では、関連付け方法を使用して製品をバンドルします。
- リンク予測:リンク予測は、データアイテム間の接続を見つけるために使用されます。 Facebook、Amazon、Netflixで採用されている推奨エンジンは、リンク予測アルゴリズムを頻繁に使用して、友人、購入するアイテム、映画をそれぞれ推奨しています。
- データ削減:データ削減方法は、多くの機能からいくつかの機能へのデータセットの簡素化に使用されます。多くの属性を持つ大規模なデータセットを受け取り、より少ない属性でそれらを表現する方法を見つけます。
モデルからアルゴリズムへの機械学習
タスクビジネス上の問題を機械学習タスクに分解すると、1つまたは複数のアルゴリズムで特定の機械学習タスクを解決できます。通常、モデルは複数のアルゴリズムでトレーニングされます。最適な結果を提供するアルゴリズムまたはアルゴリズムのセットが展開に選択されます。AzureMachine Learningには、機械学習モデルのトレーニングに使用できる30以上の事前に構築されたアルゴリズムがあります。
結論
データサイエンスは幅広い分野です。刺激的な分野です。それは芸術です。それは科学です。この記事では、氷山の表面を調べました。 「方法」がわからない場合、「方法」は無駄になります。